RL Weekly 36: AlphaZero with a Learned Model achieves SotA in Atari
Por um escritor misterioso
Last updated 04 fevereiro 2025

In this issue, we look at MuZero, DeepMind’s new algorithm that learns a model and achieves AlphaZero performance in Chess, Shogi, and Go and achieves state-of-the-art performance on Atari. We also look at Safety Gym, OpenAI’s new environment suite for safe RL.
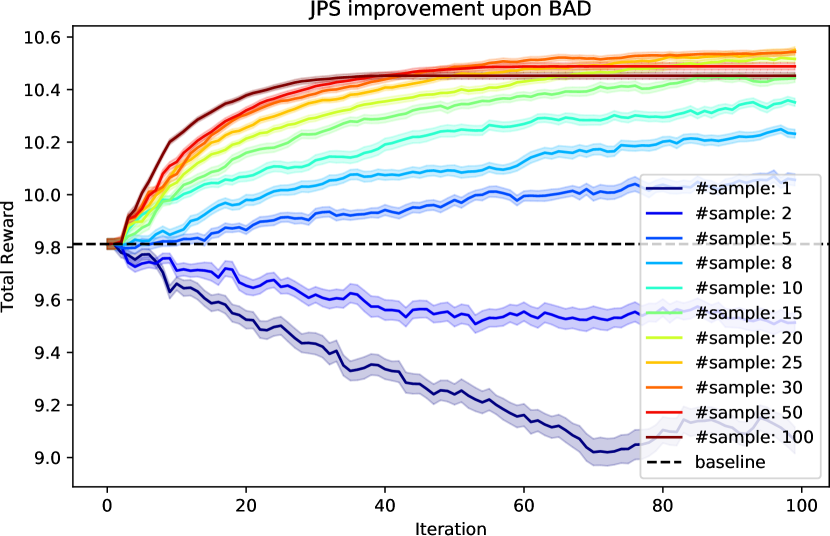
2008.06495] Joint Policy Search for Multi-agent Collaboration with Imperfect Information
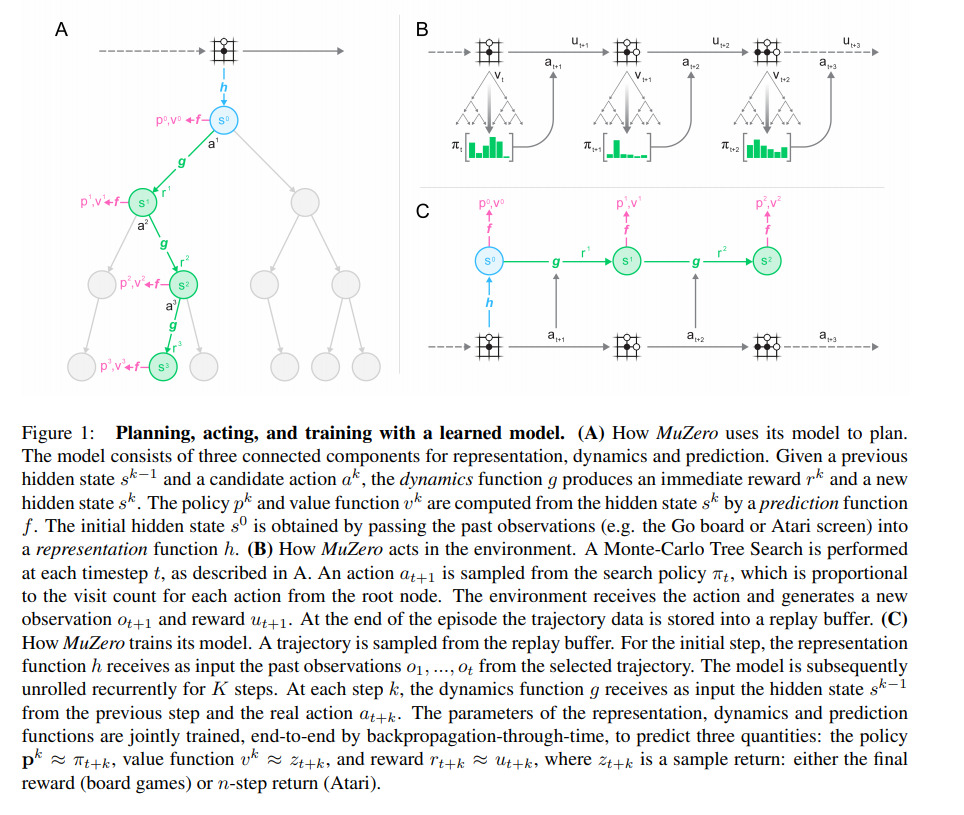
AlphaGo/AlphaGoZero/AlphaZero/MuZero: Mastering games using progressively fewer priors

PDF) Alpha-T: Learning to Traverse over Graphs with An AlphaZero-inspired Self-Play Framework

Kristian Kersting
Memory-based Reinforcement Learning
Tags

Memory-based Reinforcement Learning

PDF) Tensor Implementation of Monte-Carlo Tree Search for Model-Based Reinforcement Learning

UC Berkeley Reward-Free RL Beats SOTA Reward-Based RL
Recomendado para você
-
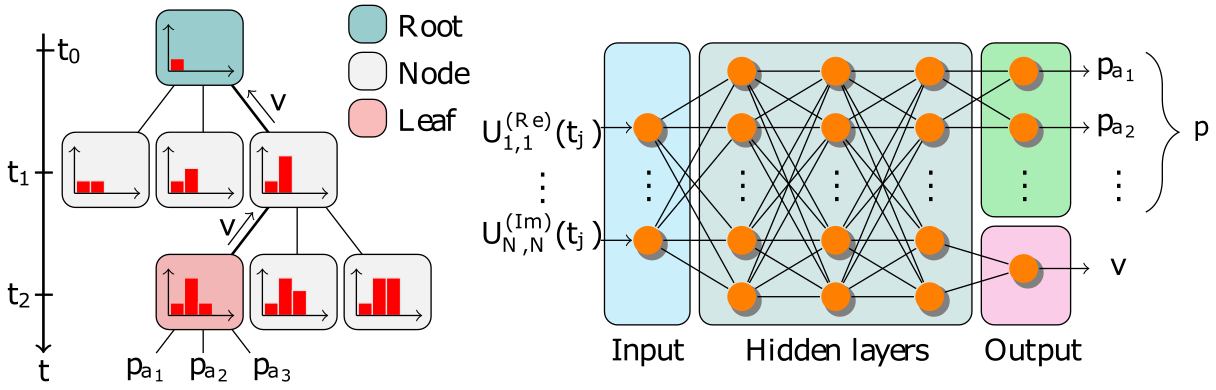 AlphaZero learns to solve quantum problems - ΑΙhub04 fevereiro 2025
AlphaZero learns to solve quantum problems - ΑΙhub04 fevereiro 2025 -
 Leela Chess Zero: AlphaZero for the PC04 fevereiro 2025
Leela Chess Zero: AlphaZero for the PC04 fevereiro 2025 -
 One Giant Step for a Chess-Playing Machine - The New York Times04 fevereiro 2025
One Giant Step for a Chess-Playing Machine - The New York Times04 fevereiro 2025 -
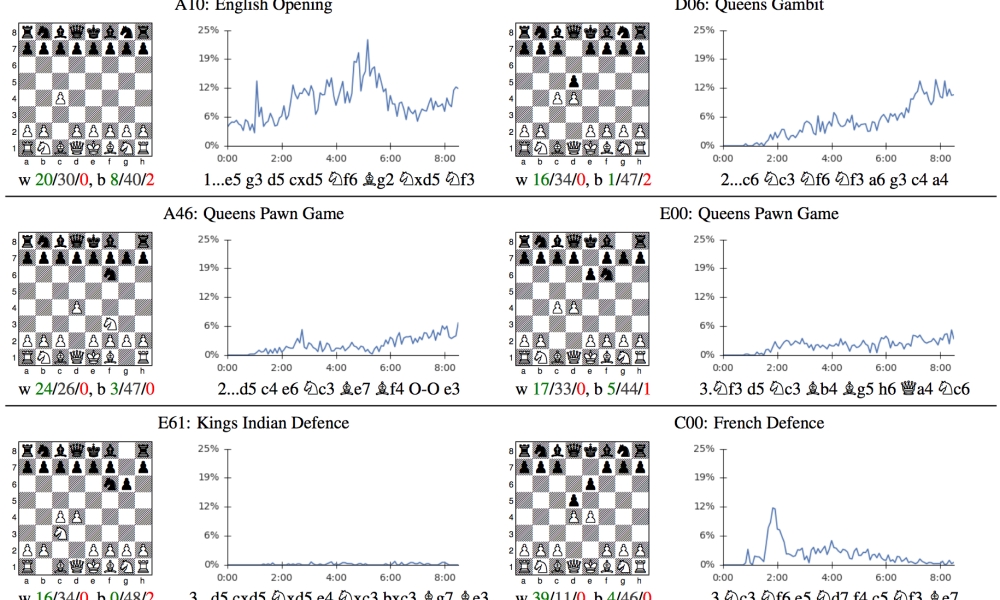
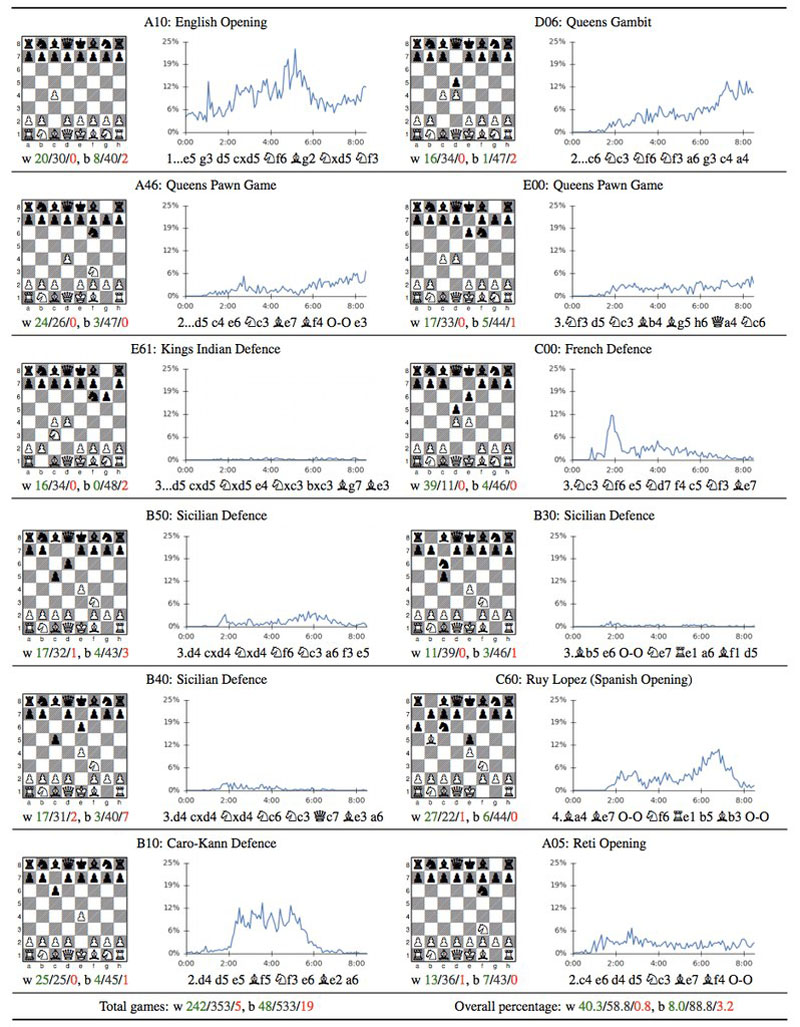 Google AI Achieves Alien Superhuman Mastery of Chess and Go in Mere Hours - The New Stack04 fevereiro 2025
Google AI Achieves Alien Superhuman Mastery of Chess and Go in Mere Hours - The New Stack04 fevereiro 2025 -
 AlphaZero Chess Engine: The Ultimate Guide04 fevereiro 2025
AlphaZero Chess Engine: The Ultimate Guide04 fevereiro 2025 -
 Deepmind's AlphaZero Plays Chess04 fevereiro 2025
Deepmind's AlphaZero Plays Chess04 fevereiro 2025 -
 AlphaZero – a generic game-beater Chess Rising Stars London Academy Shop04 fevereiro 2025
AlphaZero – a generic game-beater Chess Rising Stars London Academy Shop04 fevereiro 2025 -
 Training AlphaZero for 700,000 steps. Elo ratings were computed from04 fevereiro 2025
Training AlphaZero for 700,000 steps. Elo ratings were computed from04 fevereiro 2025 -
 A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play04 fevereiro 2025
A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play04 fevereiro 2025 -
Understanding AlphaZero Neural Network's SuperHuman Chess Ability04 fevereiro 2025

você pode gostar
-
 5 best roleplay games on Roblox in 202104 fevereiro 2025
5 best roleplay games on Roblox in 202104 fevereiro 2025 -
 A Casa do Tradutor, Albufeira. Photography Print04 fevereiro 2025
A Casa do Tradutor, Albufeira. Photography Print04 fevereiro 2025 -
 Pokémon TCG: Ho-Oh GX (21/147) - SM3 Sombras Ardentes - Pokémon Company - Jogos de Cartas - Magazine Luiza04 fevereiro 2025
Pokémon TCG: Ho-Oh GX (21/147) - SM3 Sombras Ardentes - Pokémon Company - Jogos de Cartas - Magazine Luiza04 fevereiro 2025 -
 Melhor forma de sugestão de jogos do Google Play04 fevereiro 2025
Melhor forma de sugestão de jogos do Google Play04 fevereiro 2025 -
 Las notas de todos los God of War en Metacritic04 fevereiro 2025
Las notas de todos los God of War en Metacritic04 fevereiro 2025 -
 Call of Duty: Vanguard review -- Aligning history, narrative, and gameplay04 fevereiro 2025
Call of Duty: Vanguard review -- Aligning history, narrative, and gameplay04 fevereiro 2025 -
 Aniversário - 9 Anos Theo - Planet Park Shopping Estação04 fevereiro 2025
Aniversário - 9 Anos Theo - Planet Park Shopping Estação04 fevereiro 2025 -
 ESCUDOS DE CUBA Football logo, Sports team logos, Football team04 fevereiro 2025
ESCUDOS DE CUBA Football logo, Sports team logos, Football team04 fevereiro 2025 -
 Australian Open Netflix curse: Break Point featured players lose early04 fevereiro 2025
Australian Open Netflix curse: Break Point featured players lose early04 fevereiro 2025 -
ViewSonic ELITE XG251G 25 Inch 1080p 1ms 360Hz IPS Gaming Monitor with GSYNC, HDR400, RGB Lighting, NVIDIA Reflex, and - XG251G - Computer Monitors04 fevereiro 2025
