Policy or Value ? Loss Function and Playing Strength in AlphaZero-like Self-play
Por um escritor misterioso
Last updated 23 abril 2025
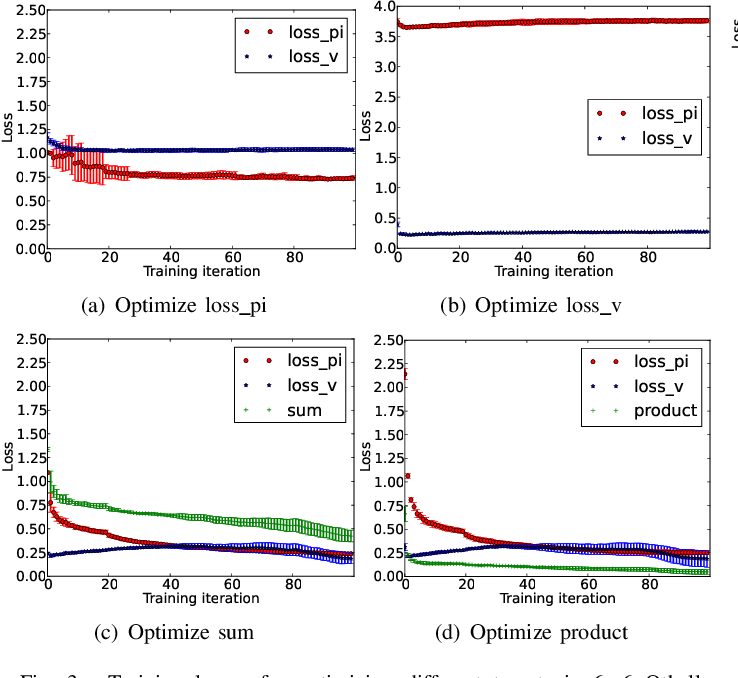
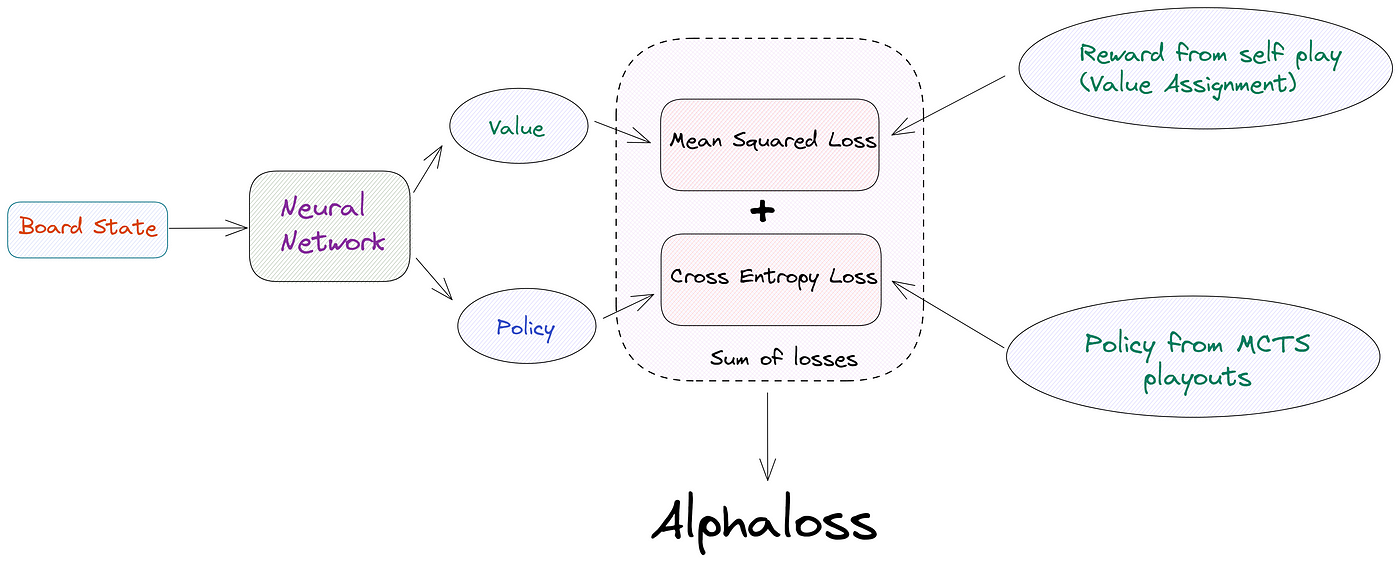
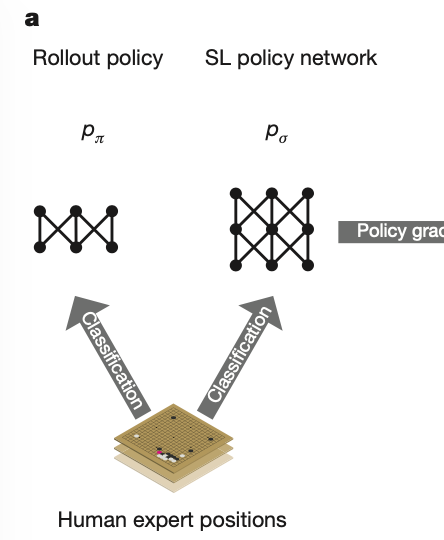
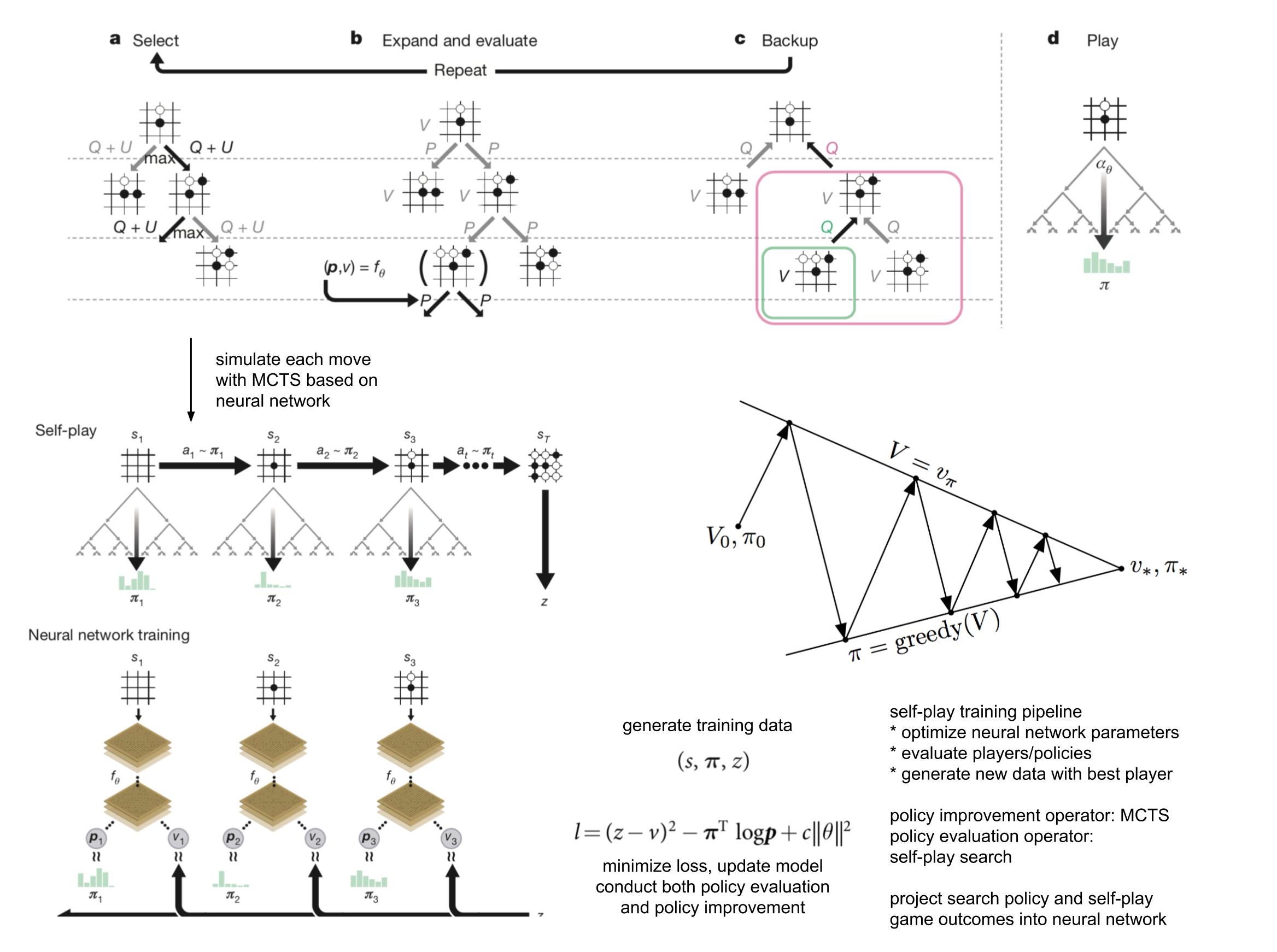
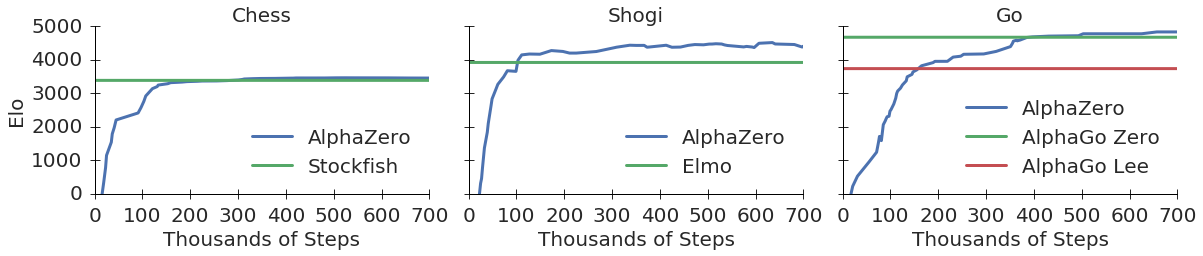
Results indicate that, at least for relatively simple games such as 6x6 Othello and Connect Four, optimizing the sum, as AlphaZero does, performs consistently worse than other objectives, in particular by optimizing only the value loss. Recently, AlphaZero has achieved outstanding performance in playing Go, Chess, and Shogi. Players in AlphaZero consist of a combination of Monte Carlo Tree Search and a Deep Q-network, that is trained using self-play. The unified Deep Q-network has a policy-head and a value-head. In AlphaZero, during training, the optimization minimizes the sum of the policy loss and the value loss. However, it is not clear if and under which circumstances other formulations of the objective function are better. Therefore, in this paper, we perform experiments with combinations of these two optimization targets. Self-play is a computationally intensive method. By using small games, we are able to perform multiple test cases. We use a light-weight open source reimplementation of AlphaZero on two different games. We investigate optimizing the two targets independently, and also try different combinations (sum and product). Our results indicate that, at least for relatively simple games such as 6x6 Othello and Connect Four, optimizing the sum, as AlphaZero does, performs consistently worse than other objectives, in particular by optimizing only the value loss. Moreover, we find that care must be taken in computing the playing strength. Tournament Elo ratings differ from training Elo ratings—training Elo ratings, though cheap to compute and frequently reported, can be misleading and may lead to bias. It is currently not clear how these results transfer to more complex games and if there is a phase transition between our setting and the AlphaZero application to Go where the sum is seemingly the better choice.

Frontiers AlphaZe∗∗: AlphaZero-like baselines for imperfect

Multiplayer AlphaZero – arXiv Vanity

A general reinforcement learning algorithm that masters chess

Train on Small, Play the Large: Scaling Up Board Games with
AlphaZe∗∗: AlphaZero-like baselines for imperfect - Frontiers

The future is here – AlphaZero learns chess

Warm-Start AlphaZero Self-play Search Enhancements
AlphaZero, a novel Reinforcement Learning Algorithm, in JavaScript

Adaptive Warm-Start MCTS in AlphaZero-Like Deep Reinforcement
AlphaZero from scratch in PyTorch for the game of Chain Reaction
The Evolution of AlphaGo to MuZero, by Connor Shorten
Reinforcement learning is all you need, for next generation

Why Artificial Intelligence Like AlphaZero Has Trouble With the

LightZero: A Unified Benchmark for Monte Carlo Tree Search in
Recomendado para você
-
 AlphaZero - Wikipedia23 abril 2025
AlphaZero - Wikipedia23 abril 2025 -
 AlphaZero Explained23 abril 2025
AlphaZero Explained23 abril 2025 -
 Contabilidade Financeira: AlphaZero23 abril 2025
Contabilidade Financeira: AlphaZero23 abril 2025 -
 engines - How is Alpha Zero more human? - Chess Stack Exchange23 abril 2025
engines - How is Alpha Zero more human? - Chess Stack Exchange23 abril 2025 -
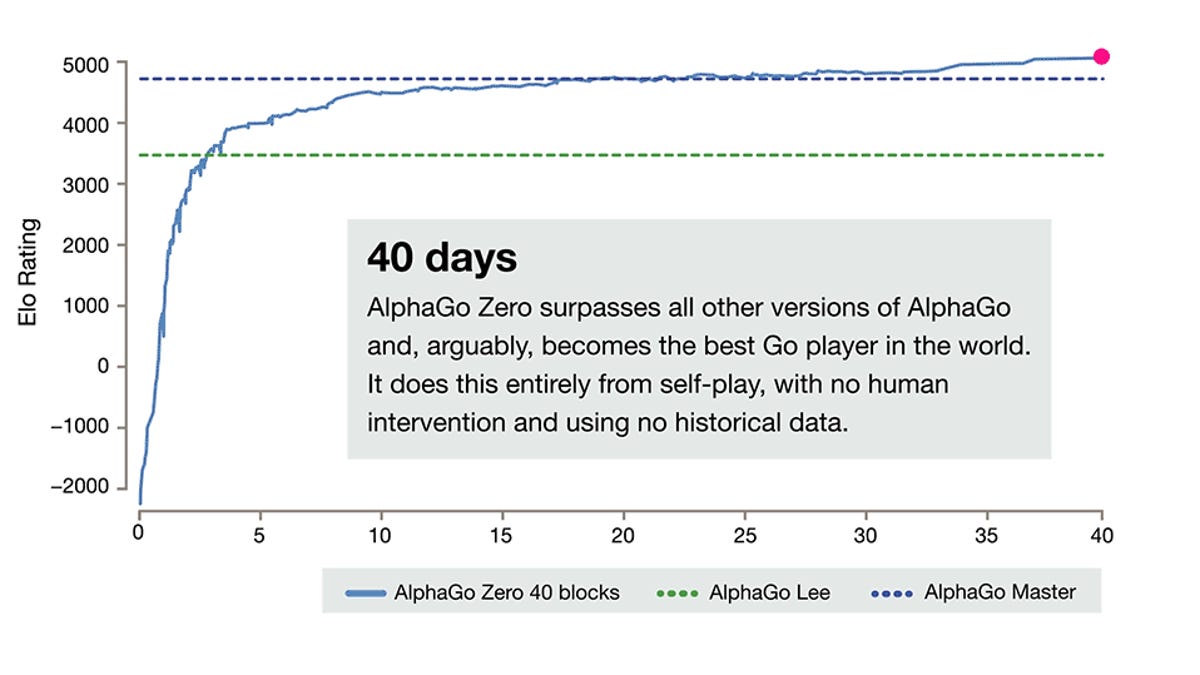 DeepMind AlphaGo Zero learns on its own without meatbag intervention23 abril 2025
DeepMind AlphaGo Zero learns on its own without meatbag intervention23 abril 2025 -
 Stockfish Robot Teaching Chess Strategy how You can Play like a Grandmaster23 abril 2025
Stockfish Robot Teaching Chess Strategy how You can Play like a Grandmaster23 abril 2025 -
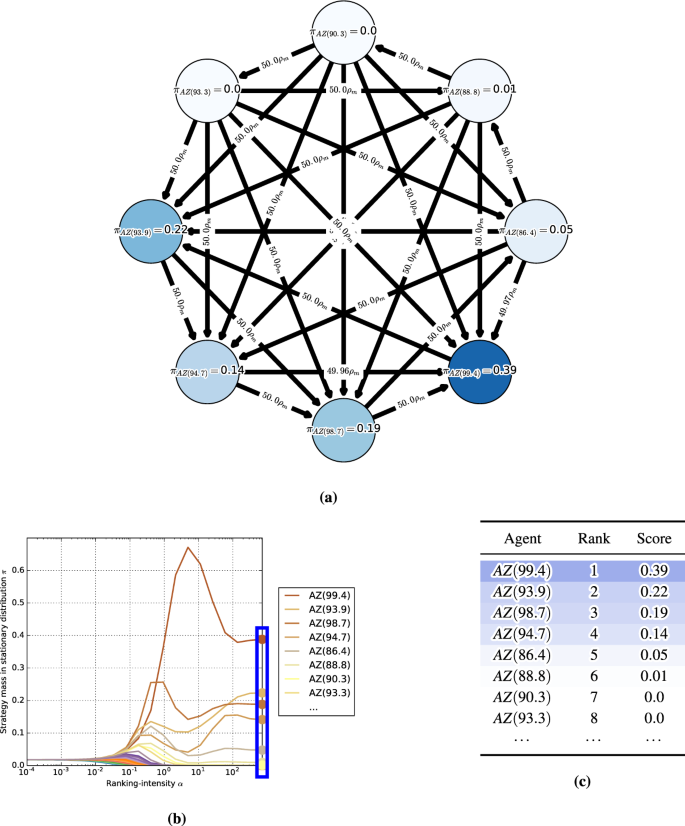 α-Rank: Multi-Agent Evaluation by Evolution23 abril 2025
α-Rank: Multi-Agent Evaluation by Evolution23 abril 2025 -
 Why DeepMind AlphaGo Zero is a game changer for AI research23 abril 2025
Why DeepMind AlphaGo Zero is a game changer for AI research23 abril 2025 -
 DeepMind AI needs mere 4 hours of self-training to become a chess overlord23 abril 2025
DeepMind AI needs mere 4 hours of self-training to become a chess overlord23 abril 2025 -
 AlphaZero Chess: How It Works, What Sets It Apart, and What It Can Tell Us, by Maxim Khovanskiy23 abril 2025
AlphaZero Chess: How It Works, What Sets It Apart, and What It Can Tell Us, by Maxim Khovanskiy23 abril 2025
você pode gostar
-
 Gold Miner Adventure - APK Download for Android23 abril 2025
Gold Miner Adventure - APK Download for Android23 abril 2025 -
 Writing Redux Reducers in Rust - Blog23 abril 2025
Writing Redux Reducers in Rust - Blog23 abril 2025 -
:no_upscale()/cdn.vox-cdn.com/uploads/chorus_asset/file/24541127/Resident_Evil_4_Chapter_9_walkthrough_37.jpg) Resident Evil 4 Grandfather Clock puzzle solution - Polygon23 abril 2025
Resident Evil 4 Grandfather Clock puzzle solution - Polygon23 abril 2025 -
Dragon Ball - Le Super Livre - Tome 02 - L'Animation 1re Partie de Akira Toriyama - Livro - WOOK23 abril 2025
-
 Compulsive event organizer QTCinderella is bringing together big23 abril 2025
Compulsive event organizer QTCinderella is bringing together big23 abril 2025 -
 Mochila Escolar Infanto- Juvenil Naruto Uzumaki Anime Desenho em Promoção na Americanas23 abril 2025
Mochila Escolar Infanto- Juvenil Naruto Uzumaki Anime Desenho em Promoção na Americanas23 abril 2025 -
 Providence Day QB Jadyn Davis commits to Michigan23 abril 2025
Providence Day QB Jadyn Davis commits to Michigan23 abril 2025 -
 TV Time - Yosuga no Sora (TVShow Time)23 abril 2025
TV Time - Yosuga no Sora (TVShow Time)23 abril 2025 -
 Download Fall Guys - Baixar para PC Grátis23 abril 2025
Download Fall Guys - Baixar para PC Grátis23 abril 2025 -
 Tensei shitara Slime Datta Ken 2 Temporada Dublado - Episódio 2 - Animes Online23 abril 2025
Tensei shitara Slime Datta Ken 2 Temporada Dublado - Episódio 2 - Animes Online23 abril 2025
